|
Shantanu Jaiswal I'm a MSR student at CMU Robotics Institute, advised by Deepak Pathak. Previously, I was a researcher at the Center for Frontier AI Research at A*STAR Singapore, where I was advised by Cheston Tan and Basura Fernando. |

|
ResearchI'm broadly interested in deep learning, computer vision and cognitive science. My recent research focuses on architectural refinements, learning methods and inference-time strategies towards more capable multimodal generative models. |
Selected Publications |
||
|
||
|
||
|
||
|
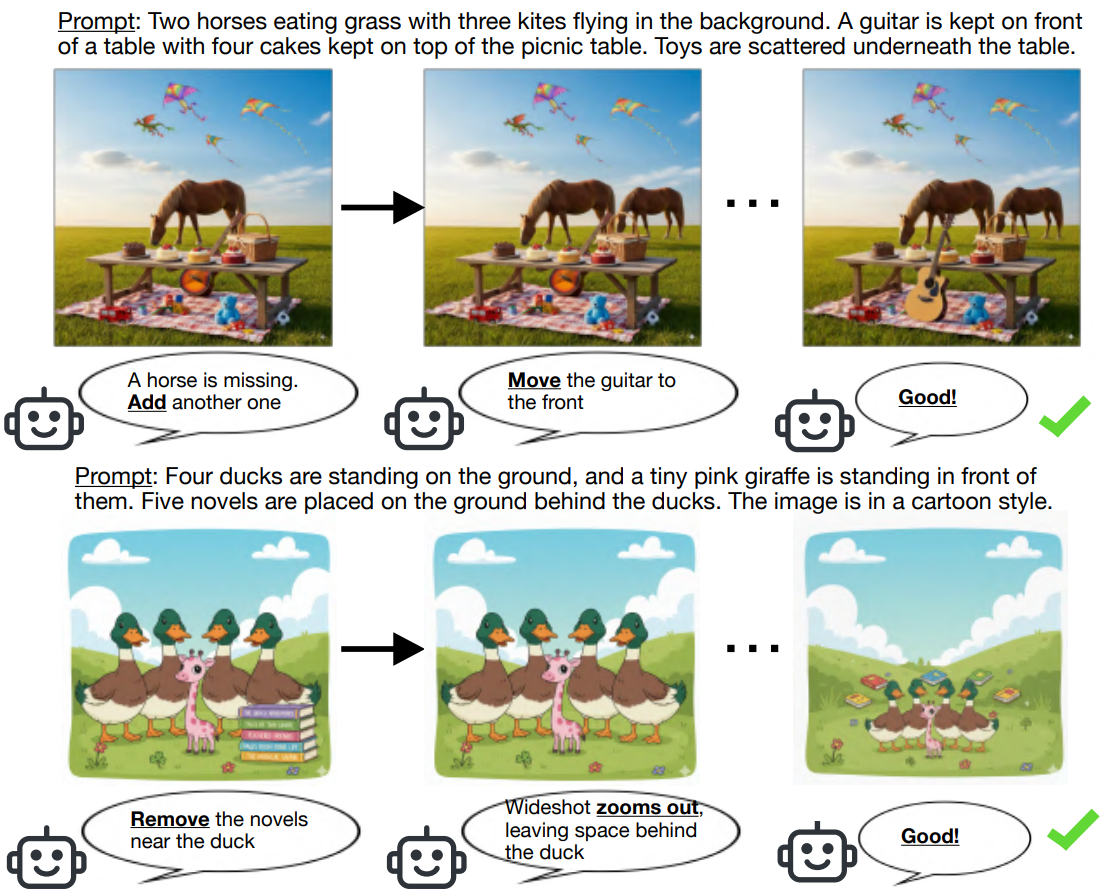
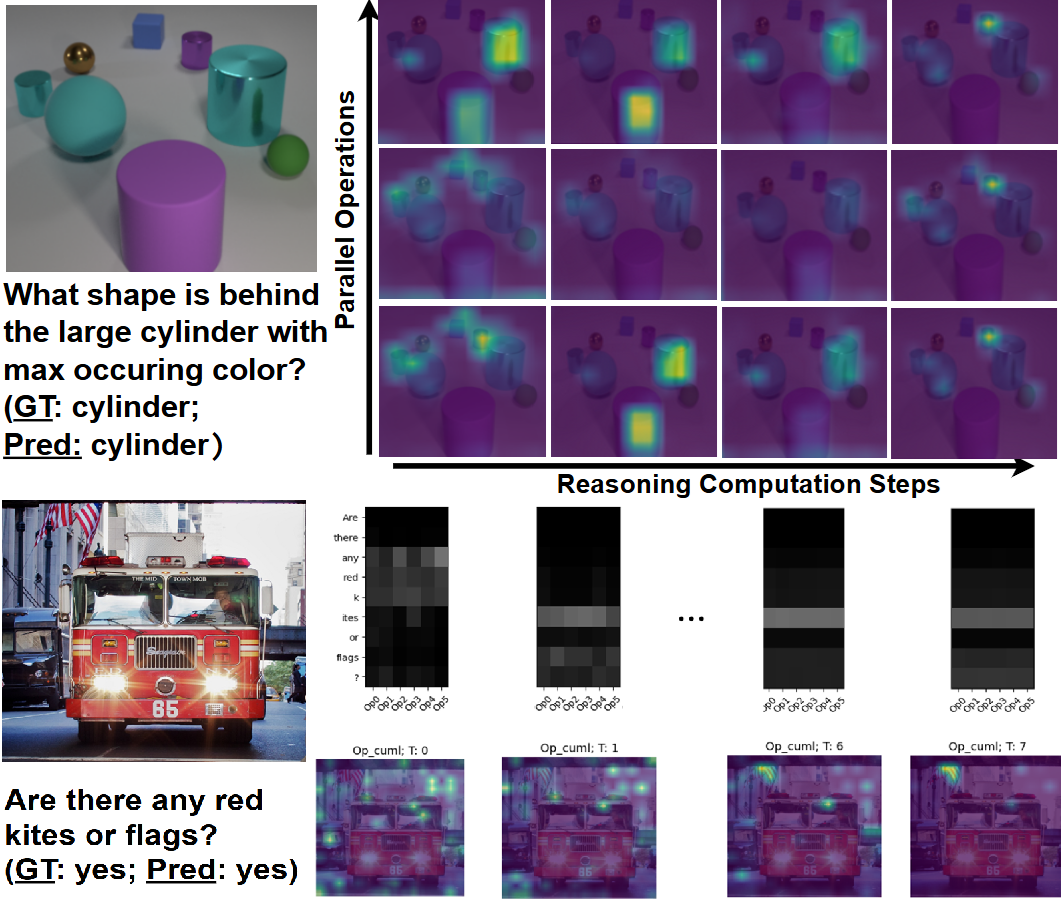
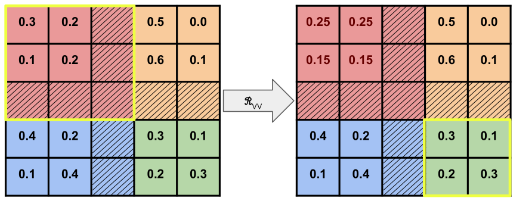
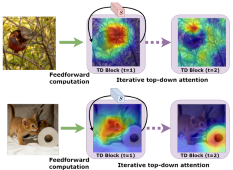
|
Website template adapted from Jon Barron.
|